Forecasting Rental Prices for Residences Through Machine Learning
In the current epoch, navigating the search for the perfect housing option that aligns with one’s budget and preferences has become increasingly challenging. House rent is influenced by various factors, including house size, number of bedrooms, locality, bathrooms, living rooms, kitchen, furnishing status, and more. Leveraging effective machine learning algorithms can streamline the process for real estate owners, aiding them in identifying ideal houses based on customers’ budgets and preferences.
The objectives of this project are twofold:
I. Develop and implement a machine learning model capable of accurately predicting house rents.
II. Identify the key features crucial for predicting house rents effectively.
To achieve these goals, the following fundamental procedures are implemented:
- Data collection
- Data Preprocessing
- Feature encoding for enhanced analysis
- Feature scaling to ensure uniformity in data representation
- Building and training the machine learning model
- Deployment
The rental price of a house is influenced by numerous factors. Through the application of suitable data and Machine Learning methodologies, several real estate platforms can identify housing options that align with the customer’s budget. If you’re interested in understanding how Machine Learning can be employed to forecast house rents, this article is tailored for you. In this piece, you will be guided through the process of predicting house rents with Machine Learning using Python.
Data Collection
The dataset employed in this project is sourced from Kaggle and encompasses details on over 3000 houses available for rent. It includes various parameters such as size, the number of bedrooms, halls, and kitchens, as well as information on locality and furnishing status, among other attributes. Moreover, the data has been appended by some randomly generated data using Python scripts.
All the required Python libraries are imported and the above-mentioned dataset.

Data Preprocessing
We can check for presence of possible dirt in the data i.e. null values or duplicates.

Feature Encoding for Enhanced Analysis
It is necessary to transform categorical features into numerical ones for effective modelling. Upon closer inspection, it becomes apparent that the categorical features consist of numerous labels. Hence, opting for one-hot encoding might result in high dimensionality. Consequently, Scikit-learn’s label encoder was employed to encode these features.

After encoding the features, we have decided to visualize the correlation of the features as shown on the heat map below:

Correlation Heatmap of the Features
Feature scaling to ensure uniformity in data representation
Validation through train-test split:
the dataset undergoes division into explanatory variables, denoted as x, and the target variable, denoted as y. subsequently, this division extends to form training and testing datasets in a ratio of 70:30, respectively. this partitioning aids in evaluating the model’s effectiveness on new data not previously encountered during training. scikit-learn’s train-test split function is employed to execute this segmentation.
Scaling features:
before delving into the modelling phase, it is essential to scale the data to address any skewed features. leveraging scikit-learn’s standard scaler ensures that, for each feature, the mean is set to 0, and the variance is standardized to 1, thereby harmonizing the magnitudes of all features. this process significantly influences the model’s overall performance.
Building and training the machine learning model
Linear Regression:
Linear regression is widely used for tasks such as predicting house prices, stock prices, sales projections, and other scenarios where understanding the relationship between variables is essential. It is a fundamental and interpretable model in the realm of supervised learning.

Decision Tree Model:
In classification tasks, the Decision Tree predicts the class label of an instance, while in regression tasks, it predicts a continuous value. The model is trained by recursively partitioning the data into subsets based on the chosen features until a stopping criterion is met.

Random Forest Model:
Random Forests are versatile and widely used in various machine learning tasks, including classification, regression, and feature importance analysis. They are robust, handle high-dimensional data well, and are less prone to overfitting compared to individual decision trees.

Performance Assessment
After training it becomes evident that the random forest model outperforms the others, achieving the highest R2 score of 0.68 and the lowest RMSE of approximately 33530.
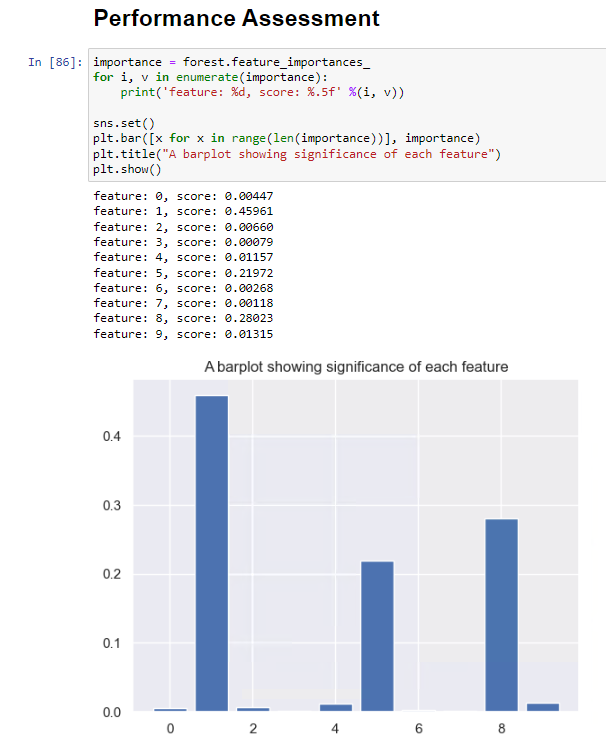
Subsequently, I proceeded to identify the features that hold significant importance by computing the feature importance scores and presenting them visually. The bar plot illustrates that the size of the house, the city where the house is situated, and the number of bathrooms significantly contribute to determining the house rent.
Neural networks:
After Feature Scaling & splitting the data into training and test sets now we will train a house rent prediction model using LSTM, LSTM stands for Long Short Term Memory Networks. It is a type of recurrent neural network that is commonly used for regression and time series forecasting in machine learning.

Deployment – Prediction using Trained Model

Conclusion
This outlines the process of employing Machine Learning to forecast the rent of residential properties. By leveraging pertinent data and Machine Learning methodologies, numerous real estate platforms efficiently identify housing options aligned with customers’ budgetary constraints. I trust you found value in this article covering the prediction of house rent through Machine Learning using Python. Please feel free to pose any insightful questions in the comments section below.