Detecting Road Lane using OPEN CV
The advent of autonomous driving cars stands out as a highly transformative breakthrough in the realm of artificial intelligence. Propelled by sophisticated Deep Learning algorithms, these vehicles play a pivotal role in propelling our society into the future and unlocking novel possibilities within the mobility sector. An autonomous car possesses the capability to navigate any route accessible to a traditional car, executing tasks with the proficiency of a seasoned human driver. However, the key lies in thorough training. Within the spectrum of training an autonomous driving car, one crucial initial phase is lane detection. In this tutorial, we will delve into the intricacies of conducting lane detection using videos.
In the realm of Road Lane Detection, the primary objective is to discern and monitor the trajectory of self-driving cars, ensuring they remain within their designated lanes and steer clear of unintended lane entries. Lane recognition algorithms serve as the linchpin in this process, consistently pinpointing the position and boundaries of lanes through meticulous analysis of visual data. These algorithms play a pivotal role in the functionality of both Advanced Driver Assistance Systems (ADAS) and autonomous vehicle systems, serving as a fundamental component. In today’s discussion, our focus will be directed towards delving into the workings of one such lane detection algorithm. The key steps in this process include:
- Video File Capture and Decoding
- Grayscale Image Conversion
- Noise Reduction
- Canny Edge Detection
- Region of Interest (ROI Selection)
- Hough Line Transformation
- Drawing Lines on Image or Video
Lane line detection using Python typically involves the integration of computer vision and image processing techniques. Here’s a brief description of the process using Python and popular libraries such as OpenCV.
Video File Capture and Decoding
Utilizing the VideoFileClip object, we initiate the video capture process. Following initialization, each video frame undergoes decoding, transforming it into a sequence of images.
All the required Python libraries are imported.

Reading the test Images: 
Grayscale Image Conversion
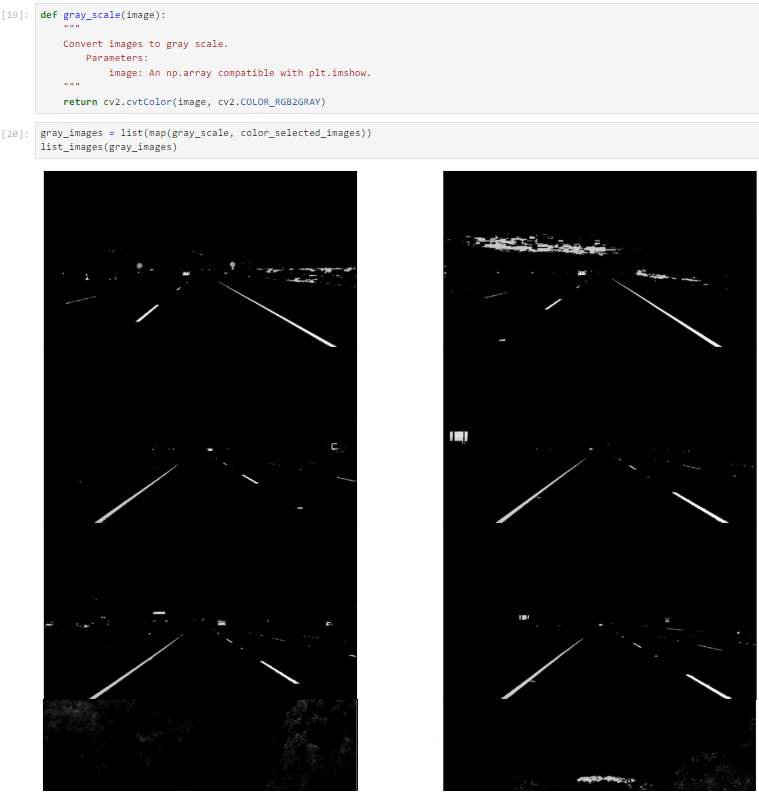
Since video frames are initially in RGB format, a conversion to grayscale becomes essential. This conversion accelerates processing, as handling a single-channel image is faster than processing a three-channel colored image.
A lot of conversions are made in process i.e. RGB Color Selection and a masked image is returned, then the HSV is calculated that is RGB2HSV, then RGB2HLS then the last step is RGB2Gray.
Noise Reduction
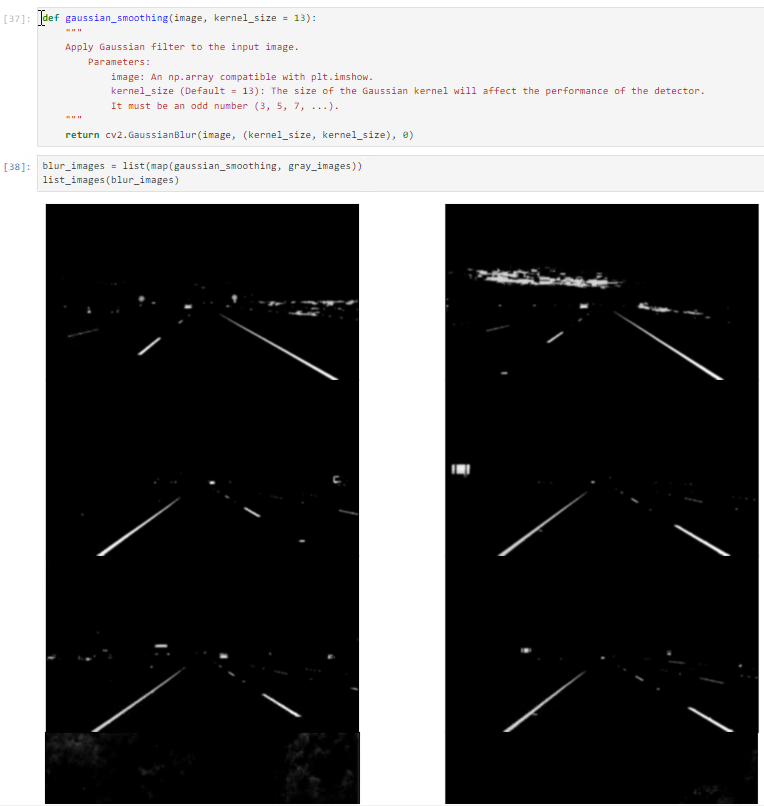
Noise can create false edges, therefore before going further, it’s imperative to perform image smoothening. Gaussian blur is used to perform this process. Gaussian blur is a typical image filtering technique for lowering noise and enhancing image characteristics. The weights are selected using a Gaussian distribution, and each pixel is subjected to a weighted average that considers the pixels surrounding it. By reducing high-frequency elements and improving overall image quality, this blurring technique creates softer, more visually pleasant images.
Canny Edge Detection
It computes gradient in all directions of our blurred image and traces the edges with large changes in intensity. By computing gradients in all directions of the blurred image, the Canny Edge Detector identifies edges with significant intensity changes. For a more detailed explanation, refer to the article on the Canny Edge Detector.

Region of Interest (ROI Selection)
Focusing solely on the road lane region, a mask is created with dimensions matching the road image. Performing a bitwise AND operation between each pixel of the Canny image and this mask reveals the region of interest defined by the polygonal contour of the mask.

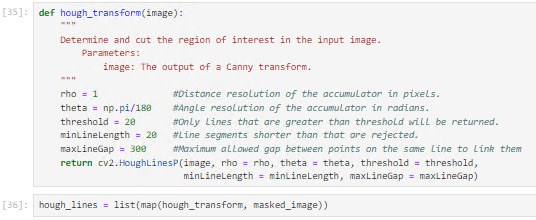
Hough Line Transformation
The Hough transformation, a feature extraction method in image processing, identifies basic geometric objects like lines. Utilizing the probabilistic Hough Line Transform in our algorithm, we convert picture space into a parameter space to accumulate voting points. This modification addresses computational complexity by randomly selecting picture points, applying the Hough transformation only to those points, and speeding up processing while maintaining accuracy in shape detection.
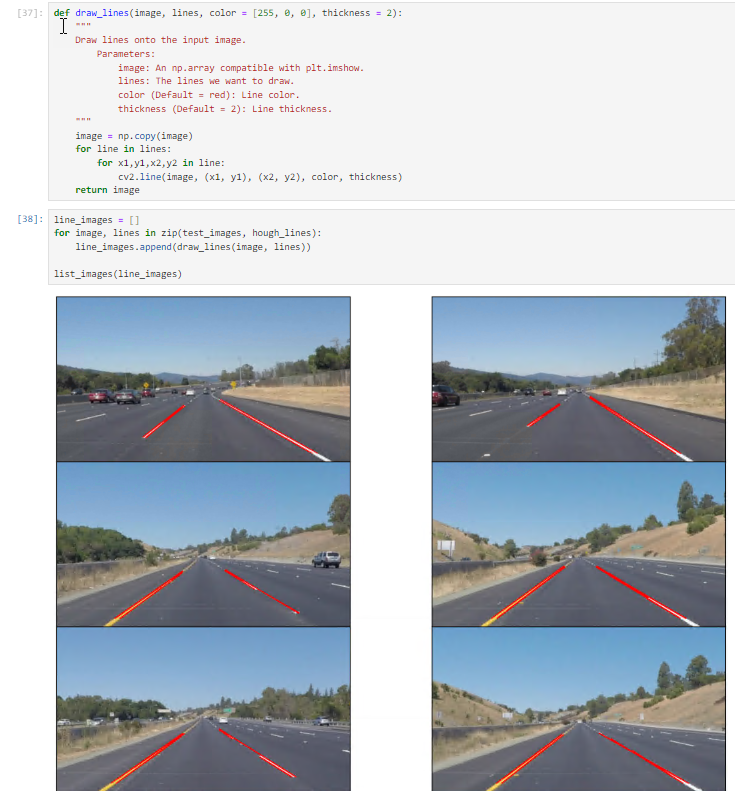
Drawing Lines on Image or Video
Following the identification of lane lines within our region of interest using the Hough Line Transform, we superimpose them onto our visual input, whether it be a video stream or an image.

CONCLUSION
Lane departure warning stands as an essential component within advanced driver assistance systems. Over the past decade, notable progress has unfolded in the realm of lane detection and tracking. The vision-based approach emerges as a straightforward method for identifying lanes. Despite considerable strides in lane detection and tracking, there remains ample room for improvement, primarily attributable to the extensive variability encountered in lane environments.