Introduction
In this topic we are using AWS resources to ingest and visualize NYC taxi sample data. This lab guides you in the process of creating AWS Lambda trigger and use of data wrangler for ingest data. As you walk through the topic you will gradually get introduced to Amazon Redshift, AWS Data wrangler, AWS Lambda, QuickSight.
Architecture Diagram

Amazon Redshift
Amazon Redshift is a fully managed cloud-based Data warehouse. To create a Datawarehouse, first you have to launch a set of nodes called an Amazon Redshift cluster. After you provision your cluster, you can upload your data set and perform data analysis queries. Redshift offers faster query performance using the same SQL-based tools.
AWS Data wrangler
An AWS Professional Service open source python initiative that extends the power of Pandas library to AWS connecting DataFrames and AWS data related services. Built on top of other open-source projects like Pandas, Apache Arrow and Boto3, it offers abstracted functions to execute usual ETL tasks like load/unload data from Data Lakes, Data Warehouses and Databases.
AWS Lambda
AWS Lambda is an event-driven, serverless computing platform provided by Amazon as a part of Amazon Web Services. In AWS Lambda the code is executed based on the response of events in AWS services such as add/delete files in S3 bucket, HTTP request from Amazon API gateway, etc. However, Amazon Lambda can only be used to execute background tasks. AWS Lambda function helps you to focus on your core product and business logic instead of managing operating system (OS) access control, OS patching, right-sizing, provisioning, scaling, etc.
AWS Secret Manager
AWS Secrets Manager is a secrets management service that helps you protect access to your applications, services, and IT resources. This service enables you to easily rotate, manage, and retrieve database credentials, API keys, and other secrets throughout their lifecycle. Using Secrets Manager, you can secure and manage secrets used to access resources in the AWS Cloud, on third-party services, and on-premises.
Prerequisites
- Make sure that you have an AWS account. To perform task in this blog, an IAM user with admin access is preferable.
- Install anaconda for having all necessary modules (Recommended)
- For local development environment following installations are required:
- AWS CLI
- AWS Data Wrangler (pip install awswrangler)
- Boto3 SDK for python (pip install boto3)
Hand’s On
- Getting Files:
- To do this, first you have to download all the taxi data from the below link: – https://github.com/ganeshmuni47/Incremental-Load-to-Redshift-using-AWS-Lambda and download the code as a zip file by clicking the code button. Extract the Zip file at your preferred location of your local system.
- Now go to your AWS console and search for S3. Create Your own bucket there, and inside that bucket create two folders one is script folder and another one is data folder.
- Upload all the data from data folder, which you have extracted before in your local system into the data folder of the S3 bucket.
- Upload SQL folder, which you have extracted before in your local system into the script folder of the S3 bucket.
- Create Role:
- Now you need to create a role for that navigate to the AWS console🡪Search for IAM🡪Role and create a role. Now attach all the required policies to the created roles.
- To attach policies to the Role, navigate to the navigating AWS console🡪Search for IAM🡪Role🡪Attach policy.
- Add all the required policies to your Role e.g., Redshift all access policy, Lambda all access policy etc.
- Create Secret in AWS Secret Manager:
- Now you have to create a secret manager for your transaction because to do secured transaction in AWS Lambda you need your credentials, so to keep your credentials encrypted you need a secret manager. you don’t need to give your credential for the connection in lambda. You just need to provide your secret manager’s name and that will internally point to your credentials.
- In this I am using my own secret manager named ‘Redshift master’.
- Create Table Schema
- In this topic You are ingesting data to the Redshift from the S3, so to do any task in Redshift, you need to create a Redshift cluster. In the cluster you have to provide the no of nodes that you want to use in your cluster in this I am using my own cluster that I have already created before.
- Now go to the Redshift query editor and then connect to any database you have and, in that database, create a schema and table for the taxi data. To create a schema and table in Redshift, see the below code.
CREATE SCHEMA taxischema;
CREATE TABLE taxischema.nyc_greentaxi(
vendorid varchar(10),
lpep_pickup_datetime timestamp,
lpep_dropoff_datetime timestamp,
store_and_fwd_flag char(1),
ratecodeid int,
pulocationid int,
dolocationid int,
passenger_count int,
trip_distance decimal(8,2),
fare_amount decimal(8,2),
extra decimal(8,2),
mta_tax decimal(8,2),
tip_amount decimal(8,2),
tolls_amount decimal(8,2),
ehail_fee varchar(100),
improvement_surcharge decimal(8,2),
total_amount decimal(8,2),
payment_type varchar(10),
trip_type varchar(10),
congestion_surcharge decimal(8,2));- Now navigate to the AWS lambda for that go to AWS Console🡪Search Lambda
- See the below screenshot how I have created an event.
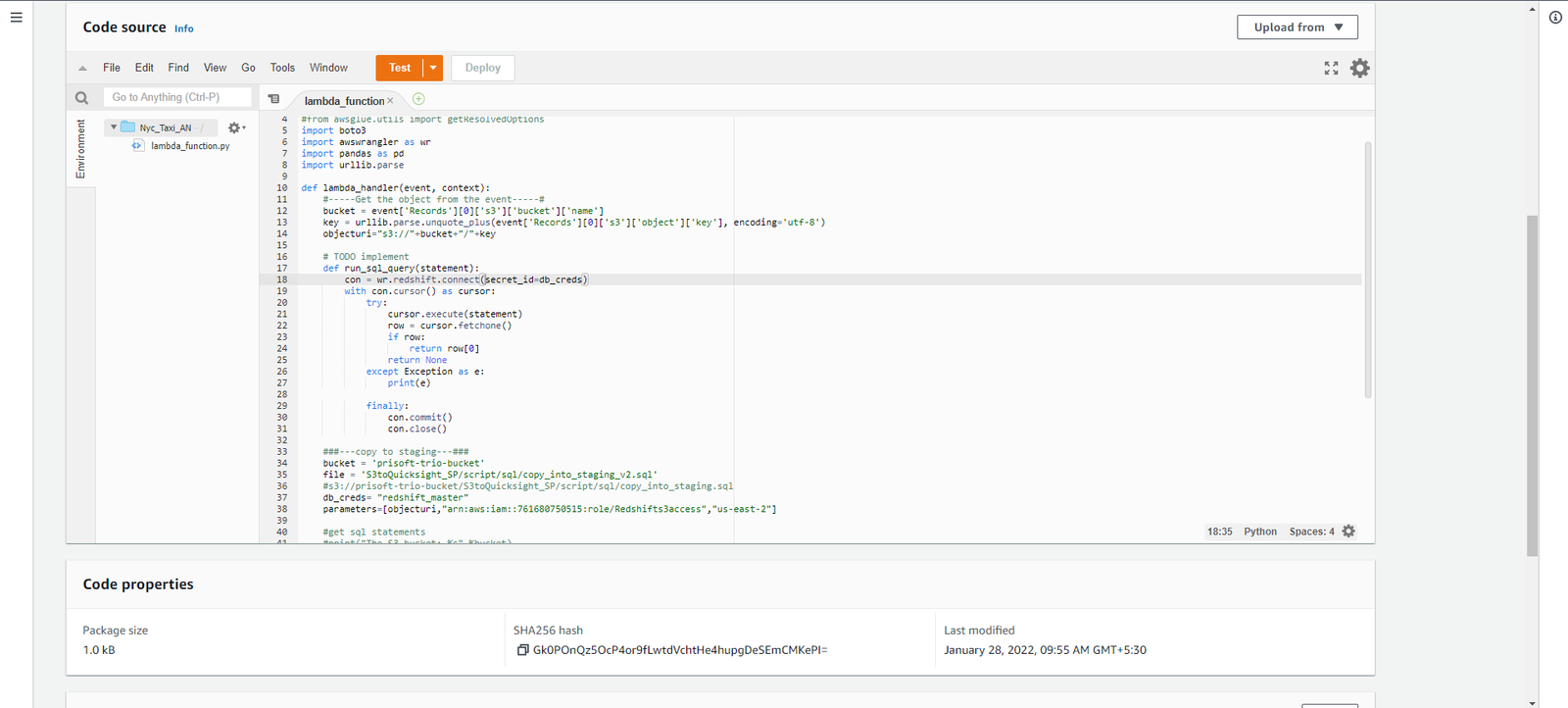
- In the above screenshot I have used the below code to create an event. Replace variables like S3 location of SQL Script, AWS Role ARN, AWS Zone , AWS Secret.
import json
import sys
import boto3
import awswrangler as wr
import pandas as pd
import urllib.parse
def lambda_handler(event, context):
#-----Get the object from the event-----#
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
objecturi="s3://"+bucket+"/"+key
# TODO implement
def run_sql_query(statement):
con = wr.Redshift.connect(secret_id=db_creds)
with con.cursor() as cursor:
try:
cursor.execute(statement)
row = cursor.fetchone()
if row:
return row[0]
return None
except Exception as e:
print(e)
finally:
con.commit()
con.close()
###---copy to staging sql file---###
bucket = 'Your_bucket_Name’
file = ‘location_of_sql_scritp’
db_creds= "Redshift_master"
parameters=[objecturi,"arn:aws:iam::***********/Redshifts3access","us-east-2"]
#get sql statements
s3 = boto3.client('s3')
sqls = s3.get_object(Bucket=bucket, Key=file)['Body'].read().decode('utf-8')
sqls = sqls.split(';')
for sql in sqls[:-1]:
sql = sql + ';'
sql = sql.format(parameters[0],parameters[1],parameters[2]).strip('\n')
print(sql)
run_sql_query(sql)
print("Task Finished")
return {
'statusCode': 200,
'body': "Task Ended"
}- Now create a S3 event trigger to execute this Lambda function. Create an S3 Object Creation event in the specified bucket with Prefix (Directory Name) and Suffix (.gz). This event will trigger Lambda whenever a file is ingested to the specified directory.
- Now in the Layer Section add AWS Data Wrangler as it is not in Lambda by default.

- Modify Configuration: After the function is created, go to Configuration > General configuration > Edit. Configure Memory (512 MB) and Timeout (5 min) for the given function.
SQL Code summary
In the above code what is happening is, any new file is coming the S3 folder, then Lambda trigger will hit the lambda function and that will load that S3 data to the Redshift table. It basically does the ETL process.
See the below SQL code which I have used in the Python Scripts for staging data in Redshift.
/*Setting up Query group */
SET query_group TO 'ingest';
/*Create a Temporary table in the Redshift with similar schema as Main Table*/
CREATE TEMPORARY TABLE nyc_greentaxi_tmp (LIKE taxischema.nyc_greentaxi);
/*Copy data from the New incoming file and store it to Temporary Table*/
COPY nyc_greentaxi_tmp FROM '{0}' IAM_ROLE '{1}' csv ignoreheader 1 region '{2}' gzip;
/*Deleting the rows that as common in both the table*/
DELETE FROM taxischema.nyc_greentaxi USING nyc_greentaxi_tmp WHERE taxischema.nyc_greentaxi.vendorid = nyc_greentaxi_tmp.vendorid AND axischema.nyc_greentaxi.lpep_pickup_datetime = nyc_greentaxi_tmp.lpep_pickup_datetime;
/*Copying data from temp table to the main table.*/
INSERT INTO taxischema.nyc_greentaxi SELECT * FROM nyc_greentaxi_tmp;
/*Deleting the temp table*/
DROP TABLE nyc_greentaxi_tmp;Data Visualization
After the data ingested into the Redshift you can visualize the data using the AWS Quick Sight for the better analysis of the data.
- Now go to the AWS console🡪search for QuickSight
- To connect the QuickSight with the Redshift, go to dataset then new dataset in QuickSight and select Redshift data source.
- Fill up all the required fields to connect with the Redshift database. See the below screenshot.
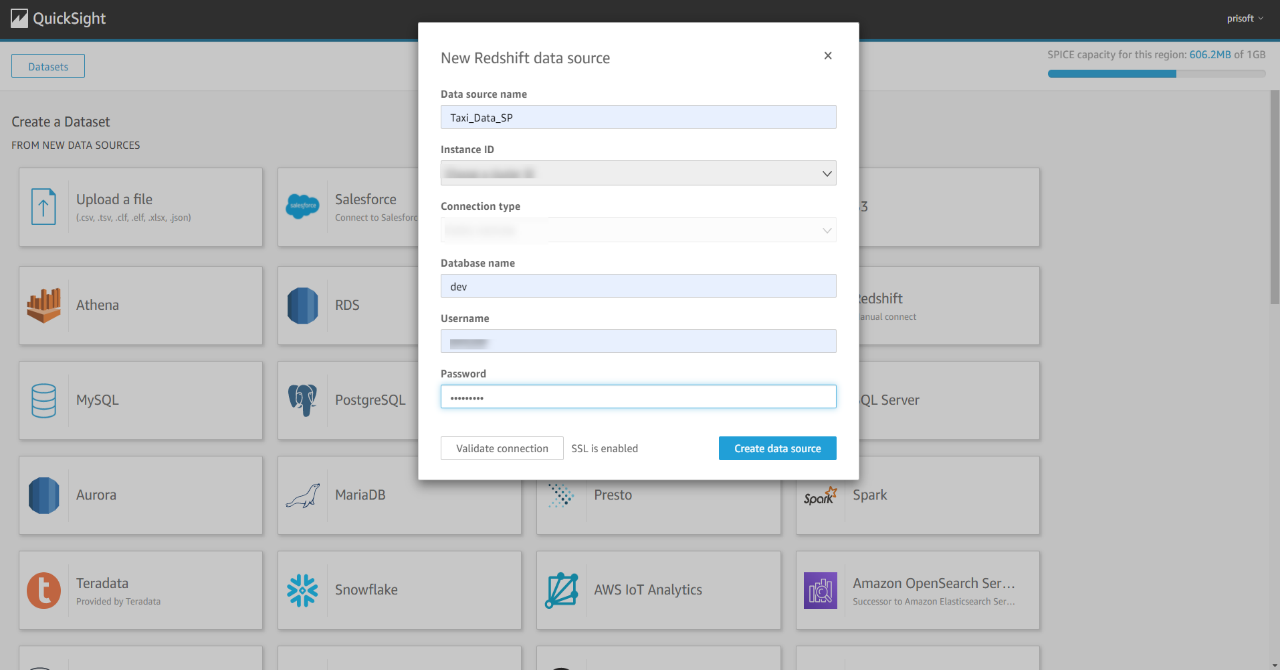
Now you can access the taxi data from the Redshift. See the below screenshot where I have created some visuals in the QuickSight using the taxi data.
Note: If this is your first time in QuickSight you will need to sign up for standard Licence. All you need is to provide a name of this QuickSight account and your email id.

Conclusion
In this ETL we are leveraging Redshift processing power with the integration capability of AWS Lambda. This is one of efficient ways to perform ETL tasks which involves Redshift. Lambda automates the whole process with event driven actions and easy integration with other AWS services.